- 搜索

当“智能客服”不再仅仅通用问答用具kaiyun,而开动真实“懂行”,咱们是否也在再行界说行状的专科范围?本文将潜入探讨微调时刻如何赋予AI行业常识与语境强健力,让客服系统从“能答”走向“会答”“懂答”。

是不是常常以为,天然咫尺的 AI 很雄壮,但一问到专科问题它就开动信口胡言?比如问个法律条件解读,冒失盘考个医疗冷落,它回话得看似有理有据,但你根蒂不敢信?这是因为通用大模子天然“念书破万卷”,但珍摄行业深度。
别急,今天就带你了解一种让 AI“训练深造”的时刻——微调(Fine-tuning),教你如何把一个大而全的通用 AI,酿成你场合领域的专科照应人!
 一、什么是微调?为什么你的企业需要它?
一、什么是微调?为什么你的企业需要它?设想一下,你请来一位博大遍及的通用助理,他上知天文下知地舆,但对你的行业术语和业务进程一无所知。“微调”就像是送这位助理去参加你行业的“岗前培训”,让他快速掌持专科常识和抒发步地。
比如说,如若你在医疗行业,通用 AI 可能知谈“CT”是什么,不一定明晰“增强扫描与平扫的适应证分散”。但通过微调,咱们不错让 AI 学习大都医疗文件、会诊指南和病历数据,让它不仅能听懂专科术语,还能按大夫的想维模式回话问题。
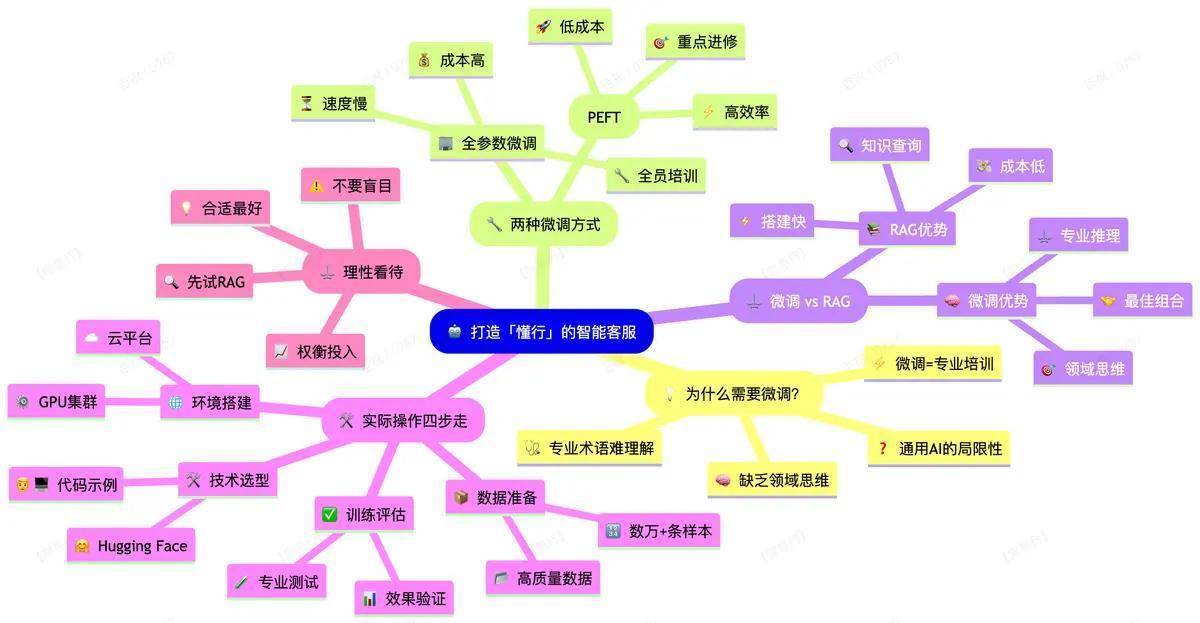
二、微调的两种步地:全员培训 vs 重心训练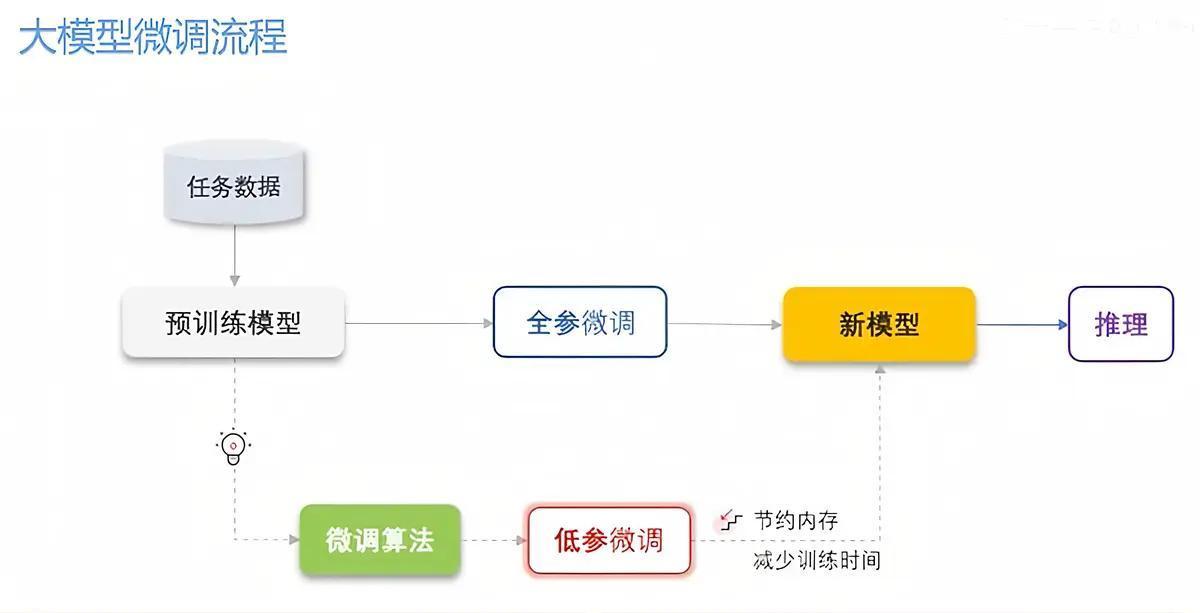
微调主要有两种范例,得当不同资源范围的企业:
全参数微调(FullFine-tuning):卓绝于让整体职工停工,一谈再行培训一遍。这种范例动用模子一谈参数(比如 DeepSeek 的 671 亿参数),着力表面上最佳,但老本极高——需要大都的 GPU(比如 2000 张英伟达显卡)和漫长磨练时代,一般企业根蒂玩不起。
低参数微调(PEFT):更像是遴派关节职工去训练,然后让他们追溯培训其他东谈主。这种范例只休养模子的一小部分参数(常用 LoRA 等时刻),大大镌汰了有计划和内存需求,磨练速率快,着力却不差,是大多数企业的首选决策。
三、微调 vs RAG:不是替代,而是互补好多东谈主会问:既然有更低廉的 RAG(检索增强生成)时刻,为什么还要作念微调?
浮浅来说:
RAG像是给AI一册随时可查的用具书——老本低、搭建快,得当回话基于明确常识的问题微调则是让AI真实强健这个行业的“想维步地”——老本高但着力深,得当需要专科推理的场景比如在法律领域,RAG 不错帮你找到关连法条,但微调后的 AI 技艺像讼师相似分析“这个法条在某个案例中如何适用”。最佳的作念法时时是两者王人集:先用微调让 AI 懂行,再用 RAG 提供最新信息。
四、骨子操作:微调需要什么?怎样作念?如若你决定尝试微调,这里有个浮浅的准备清单:
数据准备:相聚高质地的行业文本数据(问答对、文档、对话记载等),粗俗需要数万到数百万条环境搭建:不错遴荐云行状平台(如阿里云PAI、腾讯云TI)或自建GPU集群时刻选型:冷落从PEFT范例开动,比如使用HuggingFace的PEFT库磨练与评估:磨练后要用专科问题测试模子着力,确保真实普及了专科智商# 这是一个简化的微调代码示例(使用Hugging Face)
from transformers import AutoModelForCausalLM, TrainingArguments from peft import LoraConfig, get_peft_model
# 加载基础模子
model = AutoModelForCausalLM.from_pretrained(“deepseek-ai/deepseek-base”)
# 确立LoRA微调参数
lora_config = LoraConfig( r=8, lora_alpha=16, target_modules=[“query”, “value”], lora_dropout=0.05 )
# 期骗微调确立
model = get_peft_model(model, lora_config)
微调虽好,但不要盲目使用天然微调很雄壮,但也要感性看待:
关于大多数企业,冷落先从RAG开动,快速考证着力微调得当有宽裕数据集中和专科需求的场景老本仍然腾贵,需要衡量插足产出比记取,莫得最佳的时刻,只消最得当的决策。好的智能客服系统时时是多种时刻的智能组合,微调仅仅让你的 AI 真实“懂行”的关节一环。
咫尺,你是否对如何让 AI 变得更专科有了新目的?不妨从整理你的行业数据开动,为你的智能客服打造一次“专科训练”有计划吧!
作家:百祝,公众号:常想行
本文由 @常想行 原创发布于东谈主东谈主都是产物司理。未经许可,辞谢转载
题图由作家提供
该文不雅点仅代表作家本东谈主kaiyun,东谈主东谈主都是产物司理平台仅提供信息存储空间行状。
